 AID Association Initiatives Dionysiennes
AID Association Initiatives DionysiennesAccueil > Politique > La formule secrète qui a tué Wall Street
Traduction d’AID pour Les-crises.fr n° 2021-103
 La formule secrète qui a tué Wall Street
La formule secrète qui a tué Wall Street
Par Félix Salmon, traduit par Jocelyne Le Boulicaut
lundi 11 octobre 2021, par
AID soutient financièrement le très intéressant site "Les-crises.fr" depuis plusieurs années. Nous avons fait un pas de plus en participant aux traductions des textes anglais quand le site fait appel à la solidarité de ses adhérents. Nous avons donc mandaté une de nos adhérentes, Jocelyne LE BOULICAUT, enseignante universitaire d’anglais retraitée, pour y participer en notre nom et nous indemnisons son temps passé avec notre monnaie interne
La formule secrète qui a tué Wall Street
Le 23 Février 2009 par Félix Salmon
Felix Salmon (felix@felixsalmon.com) rédige le blog financier Market Movers sur Portfolio.com
Felix Salmon (@felixsalmon) est contributeur d’Idées pour WIRED. Il anime le podcast Slate Money et le blog Cause & Effect. Auparavant, il était blogueur financier chez Reuters et chez Condé Nast Portfolio. Son article de fond de WIRED sur la fonction copule gaussienne a ensuite été transformé en témoignage.
 Au milieu des années 80, Wall Street se tourna vers les « quants » – ingénieurs financiers « surdoués » – pour obtenir de nouveaux instruments permettant de gonfler les profits. Leurs méthodes pour démultiplier l’argent ont fonctionné à merveille … jusqu’à ce que l’une d’entre elles finisse par dévaster l’économie mondiale. © JIM KRANTZ / INDEX STOCK IMAGERY, INC. / GALLERY STOCK
Au milieu des années 80, Wall Street se tourna vers les « quants » – ingénieurs financiers « surdoués » – pour obtenir de nouveaux instruments permettant de gonfler les profits. Leurs méthodes pour démultiplier l’argent ont fonctionné à merveille … jusqu’à ce que l’une d’entre elles finisse par dévaster l’économie mondiale. © JIM KRANTZ / INDEX STOCK IMAGERY, INC. / GALLERY STOCK
Il y a à peine un an, le fait qu’un spécialiste des mathématiques comme David X. Li puisse un jour obtenir le « Prix Nobel d’économie » n’avait rien de choquant. Après tout, plusieurs économistes de la finance – et même des « quants » de Wall Street – ont déjà reçu le « Nobel d’économie » et les travaux du Dr Li sur la mesure du risque ont eu, plus d’impact, et plus rapidement, que toutes les contributions de ceux qui ont obtenu ce prix.
Aujourd’hui cependant, alors que banquiers, politiciens et investisseurs médusés, se penchent sur les décombres du plus grand naufrage financier depuis la Grande Dépression, Li doit probablement s’estimer heureux d’avoir encore un emploi dans la finance. Cela ne doit pas pour autant nous faire oublier ce qu’il a réussi. Il s’est attaqué à un problème notoirement difficile – déterminer la corrélation c’est-à-dire le lien de dépendance entre des événements apparemment disparates – et il l’a résolu grâce à une formule mathématique simple et élégante, devenue par la suite incontournable dans la finance mondiale.
Pendant cinq ans, la formule de Li, connue sous le nom de fonction de la copule gaussienne, est apparue sans ambiguïté comme un progrès, un bijou de la technique financière, qui permettait de modéliser les risques les plus divers et les plus complexes avec plus d’aisance et de précision que jamais auparavant. Grâce à son brillant tour de passe-passe mathématique, Li a permis aux traders de vendre d’innombrables quantités de titres financiers d’un nouveau genre, entraînant l’expansion des marchés financiers jusqu’à des niveaux jusqu’alors inimaginables.
Finalement, tout le monde ou presque a adopté sa méthode, depuis les investisseurs obligataires jusqu’aux banques de Wall Street en passant par les agences de notation et les régulateurs. Et elle leur est devenue si naturelle – et leur permettait de gagner tant d’argent –, que les mises en garde quant à ses limites ont été largement ignorées.
Et puis le modèle s’est écroulé. Les premières fissures sont apparues lorsque les marchés ont commencé à se comporter différemment de ce que les utilisateurs de la formule de Li avaient prévu. Fissures devenues fossés béants en 2008 – quand l’effondrement d’une partie du système financier a englouti des milliers de milliards de dollars, jusqu’à mettre en péril la survie de l’ensemble du système bancaire mondial.
David X. Li, on peut le dire sans prendre de risque, n’est pas près d’obtenir un prix Nobel. Une des conséquences de l’effondrement a été la fin de l’économie financière en tant que source de fierté plutôt que de crainte. Et la formule de la copule gaussienne de David X. Li restera dans l’histoire comme étant le facteur ayant contribué à provoquer les pertes insondables qui ont mis le système financier mondial à genoux.
Comment une simple formule a-t-elle pu avoir des effets aussi dévastateurs ? La réponse se trouve dans le marché obligataire, qui permet aux fonds de pensions, aux compagnies d’assurance et aux fonds spéculatifs de prêter des milliers de milliards de dollars aux entreprises, aux pays et aux acheteurs de biens immobiliers.
Une obligation n’est, bien sûr, qu’une reconnaissance de dette, la promesse de rembourser de l’argent avec intérêts à une échéance fixée. Imaginons qu’une compagnie – disons IBM – emprunte de l’argent en émettant une obligation. Alors, les investisseurs vont examiner de près les comptes de la société afin de s’assurer qu’elle a les moyens de rembourser. Plus le risque perçu est grand – et il y a toujours un risque – plus le taux d’intérêt attaché à l’obligation sera élevé.
Les investisseurs obligataires sont très à l’aise avec le concept de probabilité. S’il y a 1 % de risque de défaut de paiement, mais qu’ils obtiennent deux points de pourcentage d’intérêt supplémentaires, ils ont globalement un coup d’avance dans le jeu, comme pour un casino, qui ne craint pas de perdre de grosses sommes de temps en temps en échange de profits la plupart du temps.
Les investisseurs constituent également des « portefeuilles » de centaines, voire de milliers de créances hypothécaires (appelés en anglais « mortgage pools »). Les sommes en jeu sont ahurissantes : les prêts hypothécaires américains ont atteint plus de 11.000 milliards de dollars.
Or, ces portefeuilles ont une architecture plus complexe que la plupart des obligations. D’abord, leur taux d’intérêt n’est pas garanti, puisque la somme totale reversée chaque mois par les emprunteurs dépend du pourcentage de ménages qui remboursent (les autres faisant défaut).
De plus, Il n’y a pas non plus de date d’échéance fixe : l’argent rentre par vagues irrégulières puisque les gens remboursent leur hypothèque à des moments divers et parfois imprévisibles – par exemple, lorsqu’ils décident de vendre leur maison. Enfin – et c’est là où le bât blesse le plus – il n’y aucun moyen simple d’attribuer une probabilité aux défaillances éventuelles.
Wall Street a tenté de résoudre nombre de ces problèmes grâce à un processus appelé « titrisation » qui consiste à découper en « tranches » les portefeuilles de prêts immobiliers, permettant ainsi la création d’obligations sûres bénéficiant d’une notation triple A, pour les tranches dont il a été décidé qu’elles seront remboursées les premières. La tranche suivante n’obtiendra peut-être qu’une cote double A, mais pourra demander un taux d’intérêt plus élevé pour supporter le risque légèrement plus élevé de défaillance. Et ainsi de suite.
Si les agences de notation et les investisseurs se sentaient tant en sécurité avec les tranches AAA, c’est qu’il leur semblait impossible de voir des centaines de propriétaires faire défaut en même temps. Une personne peut perdre son emploi, une autre tomber malade. Mais il s’agit là de malheurs personnels, qui affectent peu le porte-feuille de prêts hypothécaires : les autres continuent à rembourser leur échéance en temps et heure.
Mais les calamités ne sont pas toutes individuelles, et la titrisation n’a pas encore résolu tous les problèmes liés au risque de pool hypothécaire. Certains événements, comme la chute des prix de l’immobilier, peuvent affecter un grand nombre de personnes à la fois. Si la valeur des maisons dans votre quartier baisse et que vous perdez une partie de vos actifs, il y a de fortes chances pour que vos voisins perdent aussi les leurs.
Si par conséquent vous ne remboursez pas votre prêt, il est fort probable que vos voisins aussi feront défaut. C’est cela qu’on appelle corrélation — c’est à dire la mesure selon laquelle une variable évolue en fonction d’une autre et cette corrélation entre divers événements est essentielle pour déterminer le risque associé aux obligations hypothécaires.
Tant qu’ils peuvent en fixer le prix, les investisseurs aiment le risque. Ce qu’ils détestent c’est l’incertitude – ne pas connaître le niveau de risque. Par conséquent, les investisseurs et les prêteurs hypothécaires cherchent désespérément à mesurer, modéliser et évaluer la corrélation.
Avant que n’arrivent les modèles quantitatifs, le seul cas dans lequel les investisseurs étaient prêts à mettre leur argent dans des portefeuilles de prêts hypothécaires était celui où le risque était pratiquement nul – en d’autres termes, quand ces prêts étaient implicitement garantis par le gouvernement fédéral américain au travers des institutions Fannie Mae ou Freddie Mac [sociétés d’économie mixte à capitaux privés et à mission publique, créées par le gouvernement fédéral américain dans le but d’augmenter la taille du marché des prêts hypothécaires, NdT].
Pourtant durant les années 90, avec l’expansion des marchés mondiaux, de nouveau des milliers de milliards dollars frais attendaient d’être prêtés aux emprunteurs du monde entier – pas seulement à ceux cherchant à acheter leur maison mais aux entreprises et aux acheteurs de voitures et en fait à n’importe présentant un solde créditeur – la seule condition étant que les investisseurs arrivent à chiffrer la corrélation entre ces prêts. Le problème est atrocement difficile et n’importe qui pouvant le résoudre gagnerait donc la reconnaissance éternelle de Wall Street et même vraisemblablement l’attention du comité Nobel.
 "...la corrélation est du charlatanisme" Photo : Photo AP/Richard Drew
"...la corrélation est du charlatanisme" Photo : Photo AP/Richard Drew
Afin de mieux comprendre cette histoire de corrélation, considérons un exemple simple. Imaginons une enfant dans une école primaire que nous nommerons Alice. La probabilité que ses parents divorcent cette année est d’environ 5 %, le risque qu’elle attrape des poux est aussi de 5%, la chance qu’elle voit un de ses professeurs glisser sur une peau de banane est du même ordre ainsi que la probabilité qu’elle gagne le concours d’orthographe de sa classe. Si les investisseurs échangeaient des titres cotant le risque de voir ces choses arriver à Alice, ils les évalueraient tous à peu près au même prix.
Mais si nous commençons à prendre en considération deux enfants plutôt qu’une seule, les choses changent considérablement – nous prenons en compte non seulement Alice mais aussi la fille assise à côté d’elle en classe, Britney. Si les parents de Britney divorcent, quelles sont les chances que les parents d’Alice divorcent aussi ? Toujours autour de 5% : la corrélation est donc proche de zéro. Mais si Britney se trouve avoir des poux, la chance qu’Alice en ait est alors bien plus grande, autour de 50% – ce qui veut dire que la corrélation monte à un niveau d’environ 0,5 point.
Si Britney voit un professeur glisser sur une peau de banane, quelle chance Alice a-t-elle de le voir aussi ? Très élevée, puisqu’elles sont assises l’une à côté de l’autre : elle pourrait atteindre 95%, c’est-à-dire une corrélation proche de 1. Enfin, si Britney gagne le concours de dictée, la chance qu’Alice le gagne aussi est nulle, ce qui signifie une corrélation de -1. Si les investisseurs échangeaient des titres évalués en fonction des chances que ces choses arrivent à la fois à Alice et Britney, les prix varieraient du tout au tout, du fait de cette si grande différence de corrélations.
Mais cette science est tout à fait inexacte. Le simple fait de mesurer les 5% de probabilités initiales implique de collecter de nombreuses données disparates et de les soumettre à toutes sortes d’analyses statistiques et d’erreurs. Essayer d’estimer les probabilités conditionnelles – la probabilité qu’Alice ait des poux si Britney en a – est d’un ordre de magnitude encore plus difficile à évaluer, parce que ces points de données sont bien plus rares. En raison de la rareté de données historiques, les erreurs sont donc susceptibles d’être bien plus importantes.
Dans le monde des prêts hypothécaires, c’est encore plus compliqué. Quelle probabilité y a-t-il qu’un logement donné perde de sa valeur ? L’historique du prix de l’immobilier peut en donner une idée, mais la situation macroéconomique du pays joue également un rôle important. Et quelle est la probabilité pour que, si la valeur d’un logement dans un État donné diminue, celle d’un logement similaire dans un autre État diminue également ?
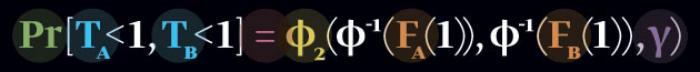 Voici ce qui a tué votre 401(k) * *[Le Plan 401(k), ou 401(k), est un système d’épargne retraite par capitalisation très largement utilisé aux États-Unis. Il tire son nom de la section 401(k) de l’Internal Revenue Code (« Code fiscal »), texte principal du droit fiscal américain, NdT].
Voici ce qui a tué votre 401(k) * *[Le Plan 401(k), ou 401(k), est un système d’épargne retraite par capitalisation très largement utilisé aux États-Unis. Il tire son nom de la section 401(k) de l’Internal Revenue Code (« Code fiscal »), texte principal du droit fiscal américain, NdT].
La fonction copule gaussienne de David X. Li a été publiée pour la première fois en 2000. Les investisseurs l’ont exploitée comme un moyen rapide - et foncièrement erroné - d’évaluer le risque. Une version plus courte apparaît sur la couverture de ce mois-ci de* Wired.
Probabilité
Plus précisément, il s’agit de la probabilité conjointe de faire défaut, c’est-à-dire la probabilité que deux membres du pool (A et B) fassent tous deux défaut. C’est ce que recherchent les investisseurs, et le reste de la formule fournit la réponse.
Temps de survie
Le temps qui s’écoule entre maintenant et le moment où l’on peut s’attendre à ce que A et B fassent défaut. Li s’est inspiré d’un concept de la science actuarielle qui décrit comment varie l’espérance de vie d’une personne lorsque son conjoint meurt.
Égalité
Un concept dangereusement précis, car il ne laisse aucune place à l’erreur. Les équations propres permettent aux quants et à leurs managers d’oublier que le monde réel contient une quantité surprenante d’incertitude, de flou et de précarité.
Copule
Cela établit une relation, couple (d’où le terme latin de copule) les probabilités individuelles associées à A et B pour obtenir un seul chiffre. Les erreurs à ce niveau augmentent considérablement le risque que l’équation entière explose.
Fonctions de distribution
Les probabilités de la durée de survie de A et B. Comme il ne s’agit pas de certitudes, elles peuvent être dangereuses : de petites erreurs de calcul peuvent vous exposer à un risque beaucoup plus important que celui indiqué par la formule.
Gamma
Le tout-puissant paramètre de corrélation, qui réduit la corrélation à une constante unique, ce qui devrait être hautement improbable, voire impossible. C’est le nombre magique qui a rendu la fonction copule de Li irrésistible.
C’est à ce moment qu’apparaît Li, mathématicien vedette. Ayant grandi dans la Chine rurale des années 60, il brille à l’école et obtient un master à l’université de Nankai avant de quitter son pays pour obtenir un ‘MBA’ à l’université Laval au Québec. Il y ajoute deux autres diplômes : un master en science actuarielle et un PhD en statistique, tous deux obtenus à l’université de Waterloo dans l’Ontario. En 1997, il pose ses bagages à la Banque Canadienne Impériale de Commerce, où sa carrière de financier commence véritablement ; Il est ensuite passé à Barclays Capital, et en 2004, il est chargé d’en reconstruire l’équipe d’analyse quantitative.
Le parcours de Li est typique de cette ère des ‘quants’ qui commença au milieu des années 80. Les universités étaient incapables de rivaliser avec les salaires exorbitants offerts par les banques et les fonds de pensions. Et dans le même temps, des légions de docteurs en mathématiques et en physiques étaient recrutés pour créer, évaluer et arbitrer les structures d’investissement toujours plus complexes de Wall Street.
En 2000, alors qu’il travaillait chez JP Morgan Chase, Li a publié un article dans le Journal of Fixed Income : « Sur les corrélations des défauts : une approche par la fonction de la copule. » (En statistiques, une copule est utilisée pour coupler les comportements de deux variables ou plus) Utilisant des calculs relativement simples – selon les normes de Wall Street en tout cas – Li a trouvé un moyen ingénieux de modéliser la corrélation des défauts sans même utiliser les données historiques de ces défauts. A la place, il a utilisé des données de marchés concernant les prix d’outils financiers connus sous le nom de dérivés sur défauts de crédit, en anglais, Credit Default Swaps (CDS).
Si vous êtes un investisseur, de nos jours vous avez le choix : vous pouvez soit prêter directement aux emprunteurs soit vendre des CDS, qui sont des assurances contre le défaut de paiement de ces mêmes emprunteurs. Dans les deux cas, vous recevrez un flux de revenu régulier – paiements d’intérêt ou primes d’assurance – et, dans les deux cas, si l’emprunteur fait défaut, vous perdez votre argent.
Le rendement dans les deux cas est pratiquement le même, mais, comme un nombre illimité de CDS peut être vendu à chaque emprunteur, l’offre de CDS, à la différence de l’offre d’obligations n’est pas limitée. Le marché des CDS a donc réussi à gonfler à une vitesse phénoménale. Bien que les CDS aient été un produit relativement nouveau lorsque l’article de Li a été publié, ils sont rapidement devenus un marché plus important et plus liquide que les obligations sur lesquelles ils reposaient.
Quand le prix d’un CDS monte, cela indique que le risque de défaut a augmenté. L’idée décisive de Li était qu’au lieu d’attendre d’avoir recueilli suffisamment de données historiques sur les défauts observés, qui sont rares dans le monde réel, il suffisait de faire appel à l’historique des prix des CDS.
Il est difficile de construire un modèle historique pour prédire les comportements d’Alice ou de Britney, mais n’importe qui pouvait voir si le prix des CDS sur les événements touchant Britney avaient tendance à évoluer dans la même direction que ceux sur Alice. Si c’était le cas, il y a alors une forte corrélation entre les risques de défaillance d’Alice et de Britney, tels que le marché les évaluent.
Li a ainsi inventé un modèle qui utilisait les prix plutôt que les données de défaut du monde réel comme raccourci (en faisant implicitement l’hypothèse que les marchés financiers en général, et les marchés des CDS en particulier, peuvent évaluer correctement le risque de faire défaut.)
On avait là la simplification brillante d’un problème insoluble. Li ne s’est pas contenté de radicalement simplifier radicalement les problèmes inhérents au calcul des corrélations ; il a décidé qu’il ne prendrait même pas la peine de cartographier et de calculer le nombre de relations proche de l’infini entre les différents titres qui composaient un portefeuille.
Qu’arrive-t-il quand le nombre de personnes dans le portefeuille augmente ou quand on mélange des corrélations positives et négatives ? Aucun problème, a-t-il répondu. La seule chose qui compte est la corrélation finale – un nombre net, simple et suffisant qui synthétise le tout.
L’effet sur les marchés de la titrisation a été foudroyant. Armés de la formule de Li, les ‘quants’ de Wall Street ont vu s’ouvrir tout un nouveau monde de possibilités. Et la première chose qu’ils ont faite a été de créer un nombre gigantesque de nouveaux portefeuilles “triple A”.
Pour les agences de notation, comme Moody’s – ou n’importe qui cherchant à modéliser le risque d’une “tranche” –, utiliser l’approche par la copule de Li signifiait qu’on n’avait plus à se préoccuper des titres sous-jacents incorporés dans ces portefeuilles. Tout ce dont elles avaient besoin, c’était ce chiffre de corrélation et elles obtenaient une note indiquant le niveau de risque de la tranche.
Par conséquent, on pouvait ficeler et transformer à peu près n’importe quoi en une obligation AAA – obligations d’entreprise, prêts bancaires, titres adossés à une créance hypothécaire ou tout ce qu’on pouvait imaginer. On parlait à leur propos de collateralized debt obligations ou CDO (en français, « obligation adossée à des actifs »).
On pouvait découper ce pool en tranches et créer ainsi des titres triple A, même si aucun des emprunts n’étaient eux-mêmes des triple A. On pouvait même prendre des tranches moins bien côtées, d’autres CDO, les regrouper – opération appelée CDO-squared. Les opérations étaient alors si éloignées des prêts, obligations ou hypothèques de départ que personne n’avait plus vraiment la moindre idée de ce que ces titres contenaient. Mais cela n’avait aucune importance : tout ce dont vous aviez besoin était la formule copule de Li.
Les marchés de CDS et CDO se sont développés de concert, se nourrissant l’un de l’autre. A la fin de l’année 2001, le marché des CDS représentait une valeur de 920 milliards de dollars. À la fin de 2007, ce nombre avait grimpé à plus de 62.000 milliards de dollars. Les marchés des CDO, qui tournaient autour de 275 milliards de dollar en 2000, représentaient 4.700 milliards de dollars en 2006.
 David X. Li Illustration : David A. Johnson
David X. Li Illustration : David A. Johnson
Et, au cœur de tout cela, on retrouvait la formule de Li. Lorsqu’on parle aux acteurs du marché, pour décrire celle-ci, ils utilisent des mots comme : « beau, simple, ou, plus généralement, efficace ». On pouvait l’appliquer partout, pour n’importe quoi, et elle a donc été rapidement adoptée, non seulement par les banques qui ont généré de nouvelles obligations, mais aussi par les traders et les fonds spéculatifs qui se sont mis à rêver de transactions complexes entre tous ces titres.
« Le monde des CDO reposait presque exclusivement sur ce modèle de corrélation de type copule » explique Darrell Duffie, professeur de finance à l’université de Stanford qui a été membre du comité de Conseil en Recherche Scientifique de Moody. La copule gaussienne est rapidement devenue un élément de langage si universellement accepté dans le monde de la finance que les courtiers se sont mis à coter les prix des tranches d’obligations sur la base de leurs corrélations « Le trading de corrélation s’est répandu dans la psyché des marchés financiers à la manière d’un virus de la pensée hautement infectieux, » a écrit la gourou des marchés de produits dérivés, Janet Tavakoli en 2006.
Les ravages qui devaient suivre étaient prévisibles et, en fait, prévus. En 1998, avant même que Li n’invente sa formule, Paul Wilmott écrivait que « les corrélations entre quantités financières sont notoirement instables. » Wilmott, consultant et conférencier en finance quantitative , affirmait qu’aucune théorie ne devrait être construite à partir de paramètres aussi imprévisibles. Et il n’était pas le seul.
Durant les années d’euphorie, tout le monde était capable d’énumérer toutes les raisons pour lesquelles la fonction de la copule gaussienne n’était pas parfaite. L’approche de Li ne tenait pas compte de l’imprévisibilité : elle supposait que la corrélation était constante plutôt que quelque chose de mercuriel. Les banques d’investissement appelaient régulièrement Duffie, notre professeur de Standford pour lui demander de venir leur expliquer ce que cachait exactement la formule de Li.
A chaque fois, il les mettait en garde, insistant sur le fait qu’elle ne permettait pas d’évaluer ou de gérer le risque.
Avec le recul, avoir ignoré ces avertissements semble bien téméraire. Mais, à l’époque, ce n’était pas aussi simple. Les banques niaient les dangers, en partie parce que les gestionnaires qui avaient le pouvoir de mettre le holà ne comprenaient pas les controverses entre les différentes factions de l’univers des ‘quants’. Mais, surtout, elles en retiraient beaucoup trop d’argent pour s’arrêter.
Dans le domaine de la finance, on ne peut jamais réduire le risque de manière absolue ; on peut seulement essayer de mettre en place un marché dans lequel les personnes qui ne veulent pas prendre de risque peuvent le vendre à ceux qui l’acceptent. Mais sur les marchés des CDO, les gens utilisaient le modèle de copule gaussienne pour se convaincre qu’ils ne prenaient aucun risque, alors que ce n’était vrai que dans 99% des cas. Ils ont fait sauter le 1% restant, or c’est justement ce qui peut annihiler tous les gains précédents, et plus encore.
La fonction copule de Li a été utilisée pour évaluer des CDO valant des centaines de milliards de dollars et regorgeant de prêts hypothécaires. Et comme la fonction copule utilisait les prix des CDS pour calculer la corrélation, elle a été obligée de se limiter à la seule période pendant laquelle ces produits ont existé, soit moins d’une décennie, période pendant laquelle les prix des logements ont explosé. Naturellement, les corrélations de défaut étaient excessivement faibles pendant ces années là. Mais, lorsque le boom des prêts hypothécaires s’est brutalement arrêté et que la valeur des maisons a commencé à chuter partout dans le pays, les corrélations ont explosé.
Les banquiers en charge de la titrisation des prêts hypothécaires savaient que leurs modèles étaient extrêmement sensibles à l’estimation des prix des maisons. Si jamais elle devenait négative à l’échelle de la nation, une grande partie des titres évalués triple A, c’est-à-dire sans risque, par les ordinateurs calculant les copules, se volatiliseraient. Mais personne n’a eu le courage d’arrêter la création des CDO et les grandes banques d’investissement ont joyeusement continué de monter de nouvelles opérations, en s’appuyant sur les corrélations des périodes pendant lesquelles le prix de l’immobilier ne faisait que monter.
« Tout le monde espérait que le prix de l’immobilier continuerait d’augmenter », raconte Kai Gilkes, de l’entreprise de recherche sur le crédit CreditSights, qui a travaillé pendant 10 ans pour des agences de notation. « Quand ils ont cessé d’augmenter, pratiquement tout le monde s’est retrouvé ‘du mauvais côté’, parce que la sensibilité aux prix de l’immobilier était énorme. Et il n’y avait aucun moyen de passer outre. Pourquoi les agences de notation n’avaient-elles pas prévu un « coussin » pour amortir cette sensibilité à un scénario de dépréciation des prix de l’immobilier ? Parce que, si elles l’avaient fait, elles n’auraient simplement jamais pu attribuer une note à un seul CDO adossé à une hypothèque. »
Les banquiers auraient dû remarquer que de très petits changements dans les hypothèses sous-jacentes pouvaient se traduire par des changements très importants dans le chiffre représentant les corrélations. Ils auraient également dû s’apercevoir que les résultats obtenus étaient bien moins volatils qu’ils n’auraient dû l’être – ce qui signifiait simplement que le risque s’était juste déplacé. Où le risque avait-t-il bien pu se nicher ?
Ils n’en savaient rien et évitaient consciencieusement de se poser la question. L’une des raisons en était que les résultats sortaient de modèles informatiques « boîte noire » et qu’il était difficile de les soumettre à un test de bon sens. Une autre des raisons en était que les ‘quants’ qui auraient dû être plus à même de percevoir les faiblesses des copules, n’étaient pas ceux qui prenaient les grandes décisions quand il s’agissait d’allouer les capitaux. Leurs managers, qui étaient les réels décisionnaires, manquaient des compétences mathématiques nécessaires pour comprendre à quoi servaient les modèles ou comment ils fonctionnaient. Ils pouvaient, par contre, comprendre quelque chose d’aussi simple qu’un chiffre donnant la corrélation. Et c’est bien de là que venait le problème.
« La relation entre deux actifs ne peut jamais être exprimée par seulement une quantité scalaire » nous explique Wilmott. Prenons l’exemple du cours des actions de deux fabricants de baskets : quand le marché des chaussures est en croissance, les deux entreprises se portent bien et la corrélation entre leurs résultats est élevée. Mais, lorsque l’une des deux gagne de la notoriété grâce à l’engouement de célébrités et commence à prendre des parts de marché à l’autre, les cours de leurs actions divergent et la corrélation entre elles devient négative. Enfin, si la nation se transforme en un pays de pantouflards affalés devant la télé, les deux entreprises entrent en déclin et la corrélation redevient positive. Il est impossible de synthétiser cette histoire en un seul chiffre, mais les CDO ont invariablement été vendus en partant du principe que la corrélation était davantage une constante qu’une variable.
 La formule secrète qui a détruit Wall Street
La formule secrète qui a détruit Wall Street
Personne ne savait tout cela mieux que David X. Li : « Très peu de gens comprennent l’essence de la modélisation, » disait-il dans le Wall Street Journal, à l’automne 2005.
« On ne peut pas faire de reproches à Li » affirme Gilkes du CreditSights. Après tout, il a juste inventé un modèle. Par contre nous devons nous tourner du côté des banquiers, qui l’ont mal interprété. Et même dans ce cas, le vrai danger n’est pas venu du fait qu’un courtier quelconque l’a adopté mais de ce que tous les traders l’ont fait. Sur les marchés financiers, lorsque tout le monde adopte le même comportement, on peut être sûr qu’on est face à la recette classique de la bulle et d’un effondrement inévitable.
Nassim Nicholas Taleb, gestionnaire d’un fonds spéculatif et auteur du livre The Black Swan, est particulièrement sévère lorsqu’on parle des copules. « Les gens se sont tous emballés pour la copule gaussienne en raison de son élégance mathématique, mais elle n’a pour autant jamais fonctionné » dit-il, « La co-association entre les titres n’est pas mesurable à l’aide de la corrélation », parce que l’histoire passée ne peut jamais vous préparer au jour où tout part en vrille. « Tout ce qui repose sur la corrélation n’est que pur charlatanisme. »
Li est et a été considérablement absent du débat sur les causes du krach. En fait, il n’habite même plus aux États-Unis. L’an dernier, il s’est installé à Pékin pour prendre la tête du département de gestion des risques de la China International Capital Corporation. Dans un entretien récent, il a semblé peu disposé à parler de son article et a déclaré qu’il ne pouvait pas parler sans l’autorisation du département des relations publiques de son employeur. Suite à diverses demandes, le bureau en charge de la communication a envoyé un courriel indiquant que Li ne faisait plus le style de travail qu’il avait dans son emploi précédent et que, par conséquent, il ne s’adresserait pas aux médias.
Dans le monde de la finance, trop de “quants” ne voient que les chiffres qu’ils ont devant les yeux et oublient la réalité concrète que ces chiffres sont censés représenter. Ils pensent pouvoir modéliser quelques années de données et en déduire des probabilités pour des événements qui ne se produisent qu’une fois tous les 10.000 ans. Les gens investissent du coup sur la base de ces probabilités sans pour autant se demander si les chiffres qui leurs sont proposés ont un quelconque sens.
Comme Li lui-même l’a dit de son propre modèle : « Le plus dangereux, c’est quand les gens se mettent à croire tout ce qui en sort. »
Version imprimable :
